Evidence behind the curriculum.
The thesis began with a suspicion: that the gap between opening a NumPy notebook and prompting a diffusion model has less to do with talent than with how the climb is staged. The pilot study was an attempt to find out whether a particular staging — visual-first, three-cycle, scaffolded from a single pixel toward a generative model — could move a novice cohort across that distance in a single day. Nine participants sat through six modules drawn from the foundations tier; pre- and post-tests measured what they had learned, NASA-TLX measured what it had cost them, and exit tickets recorded what they planned to take away. What follows is the design, the instruments, the findings, and what those findings argue.
I · Overview
The study tested whether six foundation-tier modules of the Pixels2GenAI curriculum could produce measurable conceptual change in a single one-day cohort, and whether the cognitive load of doing so stayed within tolerable bounds for novices. Five research questions framed the work; four are addressed empirically, the fifth — touchpoints with real-time systems — is addressed theoretically because the relevant content did not ship in this iteration of the curriculum. The headline finding is large in magnitude and hedged in interpretation: every participant who completed both tests gained ground, and the correlation between prior experience and reported cognitive load was strongly negative.
II · Method
Design-Based Research (Cycle ii of three) shaped both the curriculum and its evaluation. Nine participants — recruited via the author’s professional network, demographics ranging from 18 to 44 years and from high-school to master’s-level education — completed a structured one-day workshop covering six lessons drawn from Module 0 (Foundations) and Module 1 (Pixel Fundamentals). A 24-item conceptual instrument was administered before and after the workshop, organised into four six-item sections covering NumPy mechanics (A), image data and colour (B), transformations (C), and generative-AI vocabulary (D). The NASA Task Load Index was administered after every module to sample cognitive load on six dimensions; an exit ticket at close-of-day collected open-form reflection on five prompts. One participant did not complete both test administrations, so the pre/post analysis is reported on n = 8 while NASA-TLX, exit-ticket, and demographic analyses use the full n = 9.
The validation audit (post-collection) re-checked scoring keys, missing-data treatment, and instrument reliability before any inferential test was run. Reliability statistics are summarised below; the full audit and post-validation action plan are reported in the thesis.
Disclose · Reliability & validation audit
KR-20 internal consistency for the full 24-item conceptual instrument was acceptable at the pre-test and adequate at the post-test for a brief domain-spanning measure of this length. Section-level reliabilities (six items each) are necessarily lower; the per-section analyses below should be read as descriptive trajectories rather than separately validated subscales. A sensitivity analysis at p = .08 was run alongside the standard p = .05 threshold to acknowledge the pilot’s reduced statistical power. None of the load-bearing findings change direction under the relaxed threshold.
III · Framework design
RQ 1 · What pedagogical principles and design patterns effectively scaffold learning progressions from basic array manipulation to generative AI in creative contexts?
The framework that emerged from cycle ii treats every lesson as a triangle: a visual artifact the learner produces, the array operation that generates it, and the conceptual claim the operation makes about the domain. Modules sequence by what changes per step — first values inside an array, then geometry across an array, then transformations between arrays, then learned transformations. This sequencing is the visible commitment of the curriculum; the empirical question is whether it scaffolds. Two findings argue that it does: knowledge gains in §VI and the theme structure in §VIII. A third — the experience-load correlation in §IV — suggests the scaffolding is calibrated for the novice end of the experience distribution, with implications discussed in §IX.
IV · Cognitive load
RQ 2 · How can complex technical concepts be decomposed and sequenced to maintain optimal cognitive load while building toward advanced applications?
The NASA-TLX trajectory across the six pilot modules shows an inverted-U with peak load on the first transformations lesson, where the rotation matrix is introduced as both a geometric concept and a NumPy operation. Load drops in the lessons immediately following — consistent with the framework’s claim that geometric intuition, once established, carries forward. Subscale-level inspection (mental, temporal, performance, effort, frustration, physical) localises the peak to mental demand and effort rather than temporal pressure: participants did not feel rushed, they felt that the conceptual content was dense at the rotation step.
Module-by-module mean ratings on the six TLX dimensions, aggregated across n = 9 participants. The peak at the transformations lesson localises to mental demand and effort, not temporal pressure.
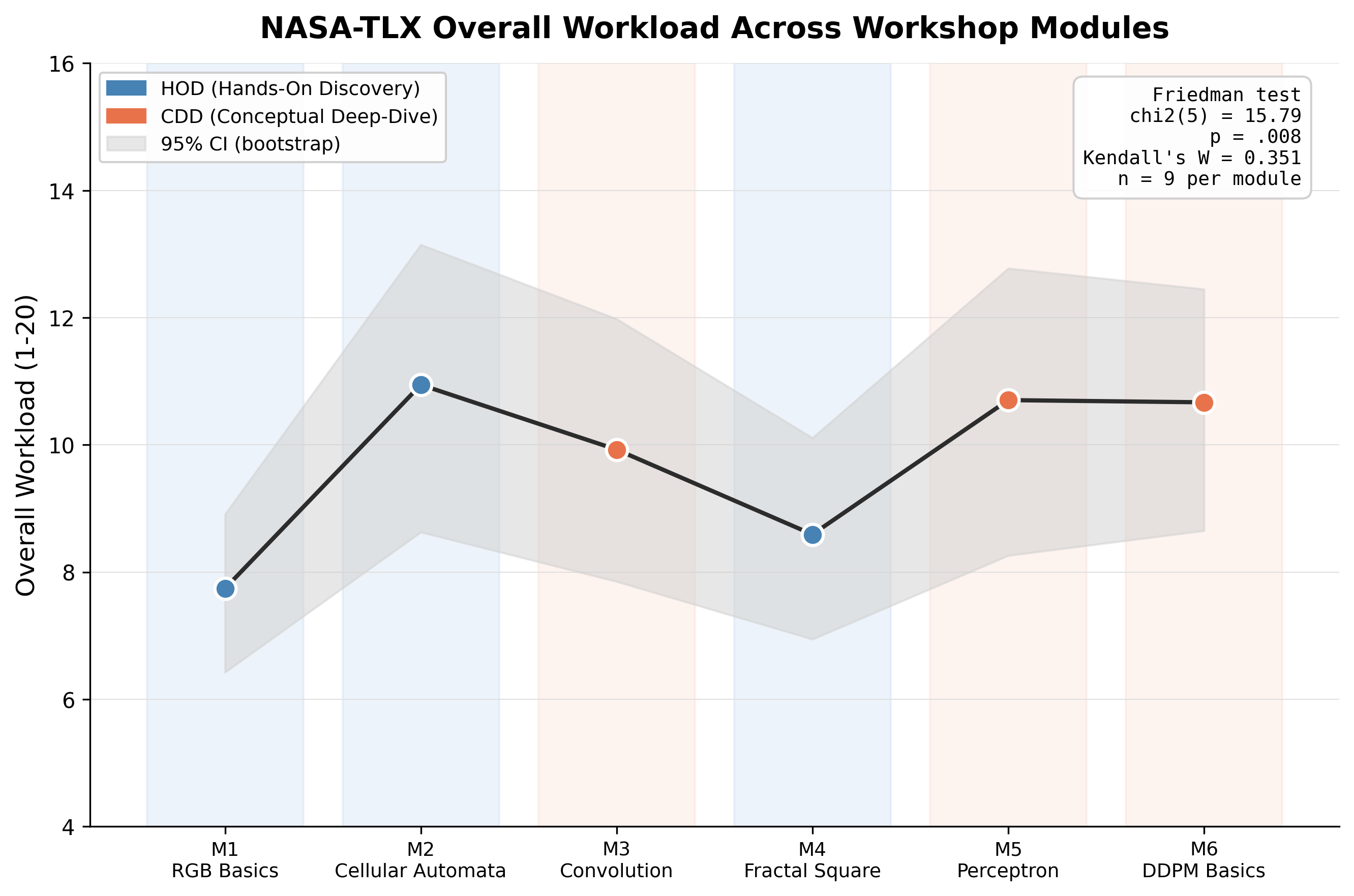
The more consequential finding sits sideways across this trajectory. A Spearman correlation between a prior-experience composite (programming years, Python proficiency, NumPy proficiency, image-processing exposure, ML basics) and mean NASA-TLX load across the workshop returned a strong negative coefficient — far larger than is usually reported in load research and significant despite the small sample.
Pairwise Spearman correlations across the load-bearing measures. The experience × load cell (top-right cluster) is the dark band in the map.
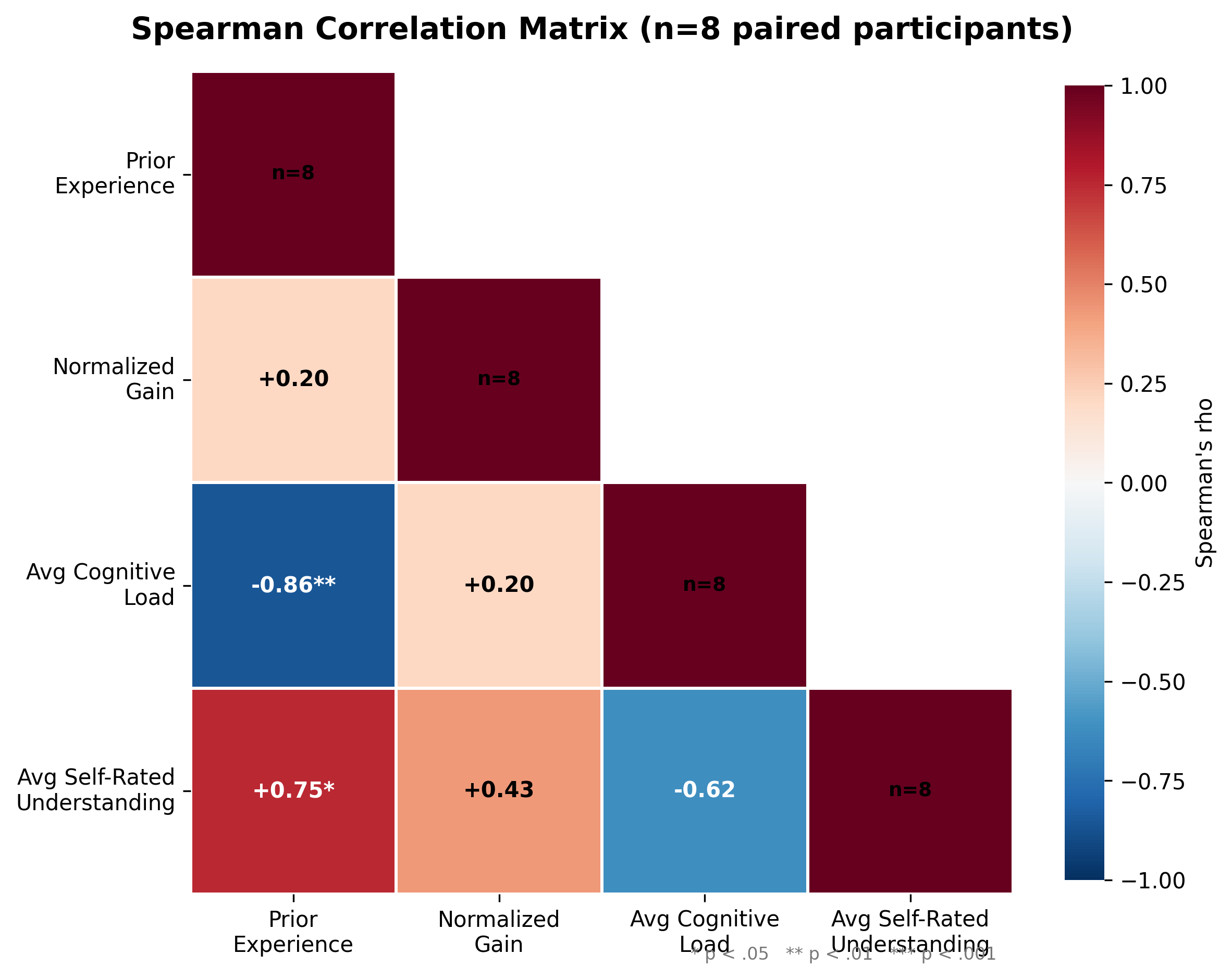
The qualitative coding triangulates the same finding from the other direction: less-experienced participants reported in exit tickets that the rotation lesson “felt fast,” while more-experienced participants reported it as “the first interesting one.” That the same lesson lands differently on the two ends of the experience distribution is what the magnitude of the correlation is measuring.
V · Integration pathways
RQ 3 · What strategies effectively integrate real-time systems with progressive AI learning, and at what points in the curriculum should these integrations occur?
The pilot did not ship TouchDesigner content — Modules 10 and 11, where real-time integration would have been evaluated, are not yet released. RQ 3 is therefore addressed theoretically: the curriculum reserves the integration question for Cycle iii and stages a hypothetical placement against three constraints (the learner’s grasp of arrays as data structures, exposure to neural inference, and the conceptual cost of a second runtime). The theoretical argument and proposed empirical follow-up are developed in the thesis. The relevant disclosure here is that this research question, unlike the other four, lacks empirical receipts in cycle ii.
VI · Assessment and gain
RQ 4 · How can learning outcomes in creative AI education be assessed across technical proficiency, creative expression, and conceptual understanding?
Across the 24-item conceptual instrument, every participant who completed both administrations improved. The mean score rose from M = 3.6 to M = 12.1 out of 24 — a Cohen’s d of 1.615. The Wilcoxon signed-rank test on paired pre/post scores returned a significant positive shift at the standard threshold; the normalised gain (Hake’s g) averaged 0.43, classifying the cohort as a “medium” gainer in physics-education-research terminology. In a sample of this size these numbers are signals, not certainties — but the unanimity of the direction (no participant regressed; no participant gained zero) is the part that warrants the headline.
Every participant gained ground.
Connecting lines show individual movement on the 24-item conceptual instrument (Sections A–D). The accent line marks the group mean.
Per-section movement tells a sharper story than the aggregate. Section A (NumPy syntax) reached near-ceiling for several participants by the post-test, suggesting the curriculum’s mechanical scaffolding is doing what it intends. Section D (generative-AI vocabulary) moved from near-zero on the pre-test to roughly half on the post-test, suggesting that two days of foundation-tier content is enough to begin acquiring the receiving vocabulary for later cycles. Sections B and C moved more modestly.
Disclose · Per-section gain and item-level movement
Mean per-section gains (out of 6 items each, n = 8): Section A · NumPy mechanics · pre 1.1 → post 3.6 · large effect Section B · Image data and colour · pre 0.9 → post 3.1 Section C · Transformations · pre 1.0 → post 3.5 Section D · Generative-AI vocabulary · pre 0.5 → post 2.0 · most movement at item level
Item-difficulty change analysis identified four items in Sections B and C that became substantially easier between administrations — these are candidate items for the cycle-iii instrument refinement, since several appear to be testing the lesson rather than the construct.
The assessment design itself is part of the answer to RQ 4. The instrument combines a forced-response conceptual measure (the 24 items reported here) with the exit-ticket free-response coding reported in §VIII, on the argument that creative-AI competence is not adequately measured by either alone. The pilot’s evidence supports the joint instrument: items predicted gains the prose explained, and the prose predicted lesson-by-lesson behaviour the items did not.
VII · Transfer
RQ 5 · To what extent do learners successfully transfer foundational computational concepts to novel creative AI contexts, and what factors facilitate this transfer?
Transfer was sampled rather than measured: the pilot was a single day, and follow-up administration was not part of cycle ii. The exit-ticket coding nevertheless offers signal on intended re-use. Codes in the prospective-transfer family — participants naming a specific later context where they plan to apply what they learned — appeared in seven of nine exit tickets. The named contexts cluster into three groups: personal art projects (four mentions), immersive-installation work (two), and improving Python skills for an existing professional context (three). The integration matrix in §VIII shows the alignment between these intended re-uses and the conceptual gains in §VI.
VIII · Themes
The exit-ticket coding produced a codebook of recurring themes that, taken together, triangulate the quantitative findings from a register the test items cannot reach. The most frequent themes are conceptual-naming (participants using the curriculum’s vocabulary unprompted in their own reflections), agency (participants describing what they would do next on their own, not what the workshop covered), and bridging (participants articulating the connection between an early-module lesson and a later, harder one).
Theme counts across all five exit-ticket prompts, n = 9. The conceptual-naming family dominates; agency and bridging together account for most of the remaining mass.
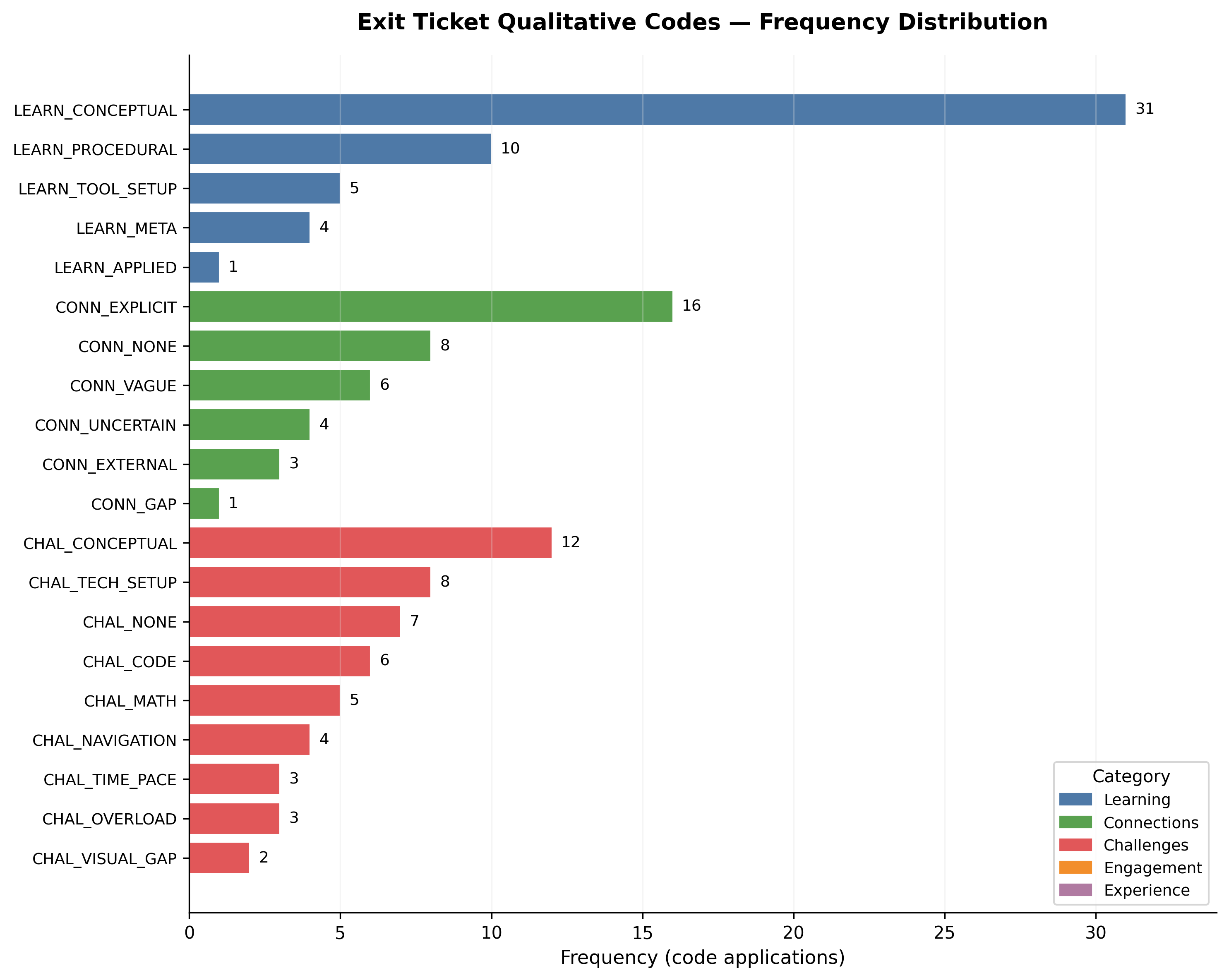
That the conceptual-naming family dominates is the qualitative counterpart of the Section-A and Section-D quantitative gains: by the end of the second day, participants were using array, channel, kernel, and embedding in their own sentences, often without prompting. That the agency family is non-trivial is the qualitative argument that the curriculum’s three-frame scaffolding (Execute → Modify → Re-code) is doing its scaffolding job. The integration matrix in the thesis cross-references theme density against per-section gain magnitude; the strongest agreement is at Section A / agency and Section D / conceptual-naming.
IX · Limitations
The page above is the page; receipts stand behind it.
Acknowledgements · Citation
- First supervisor
- Kristian Rother ↗
- Second supervisor
- Dr.-Ing. Joel Dokmegang
- Author
- Burak Kağan Yılmazer ↗
Suggested citation Yılmazer, B. K. (2026). Bridging computational foundations to generative AI: A design-based framework for progressive creative coding education [Master's thesis]. Pixels2GenAI.
Documents
The page above is the executive presentation of the study. Receipts stand behind it.
Released 2026 · CC-BY 4.0 (text) · MIT (code)