9.1.2 Backpropagation Visualisation
Train a 2-2-1 network on the XOR problem the perceptron couldn't solve. Watch the chain rule propagate gradients backward through the hidden layer, and visualise the decision boundary as it warps from a straight line into a curve.
Big question
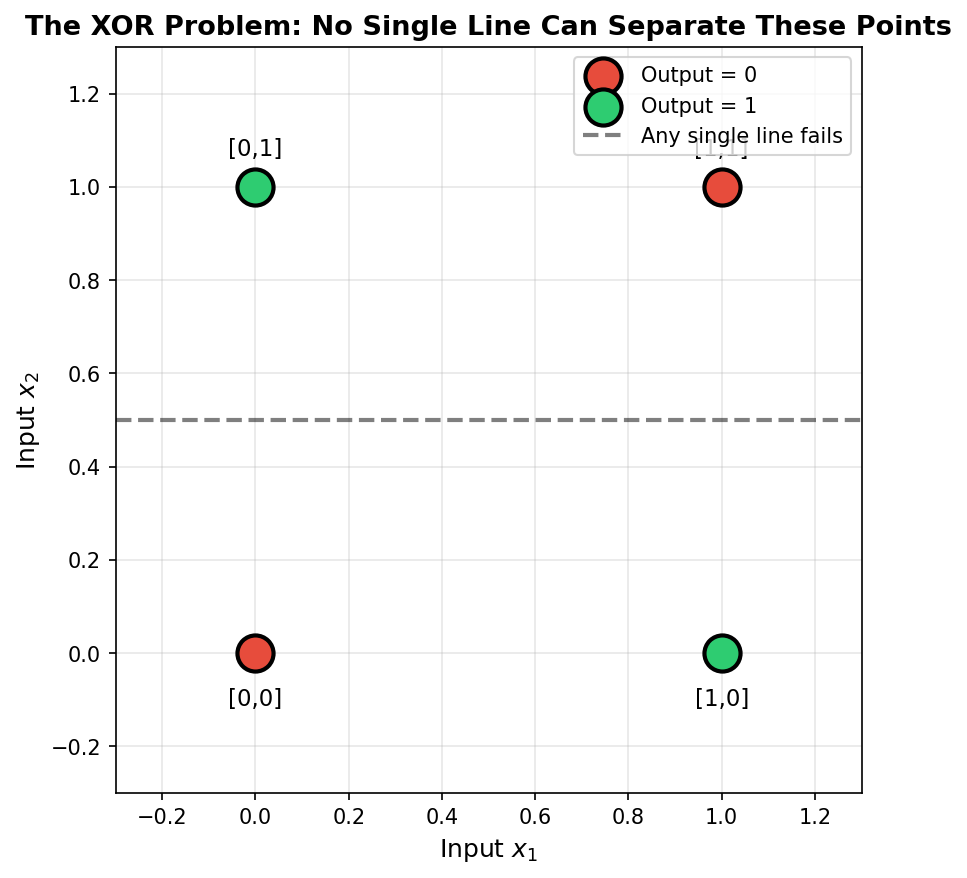
How does a neural network with hidden layers learn? A single perceptron can’t solve XOR — there is no straight line that separates the points. Adding a hidden layer of perceptrons gives the network enough flexibility to learn a curved boundary, but presented a new problem: how do you adjust the hidden weights when you can only observe the output error? The answer is backpropagation, the chain-rule trick rediscovered for neural networks by Rumelhart, Hinton, and Williams in 1986 [1]. This lesson trains a 2-2-1 network on XOR and traces each gradient step so the math feels concrete.
Learning objectives
- Build a tiny network with two inputs, two hidden neurons, and one output — about 9 parameters total.
- Run the forward pass to compute hidden activations and output prediction.
- Run the backward pass to compute gradients via the chain rule.
- Apply gradient descent updates to all weights and watch the XOR problem solve over ~1000 epochs.
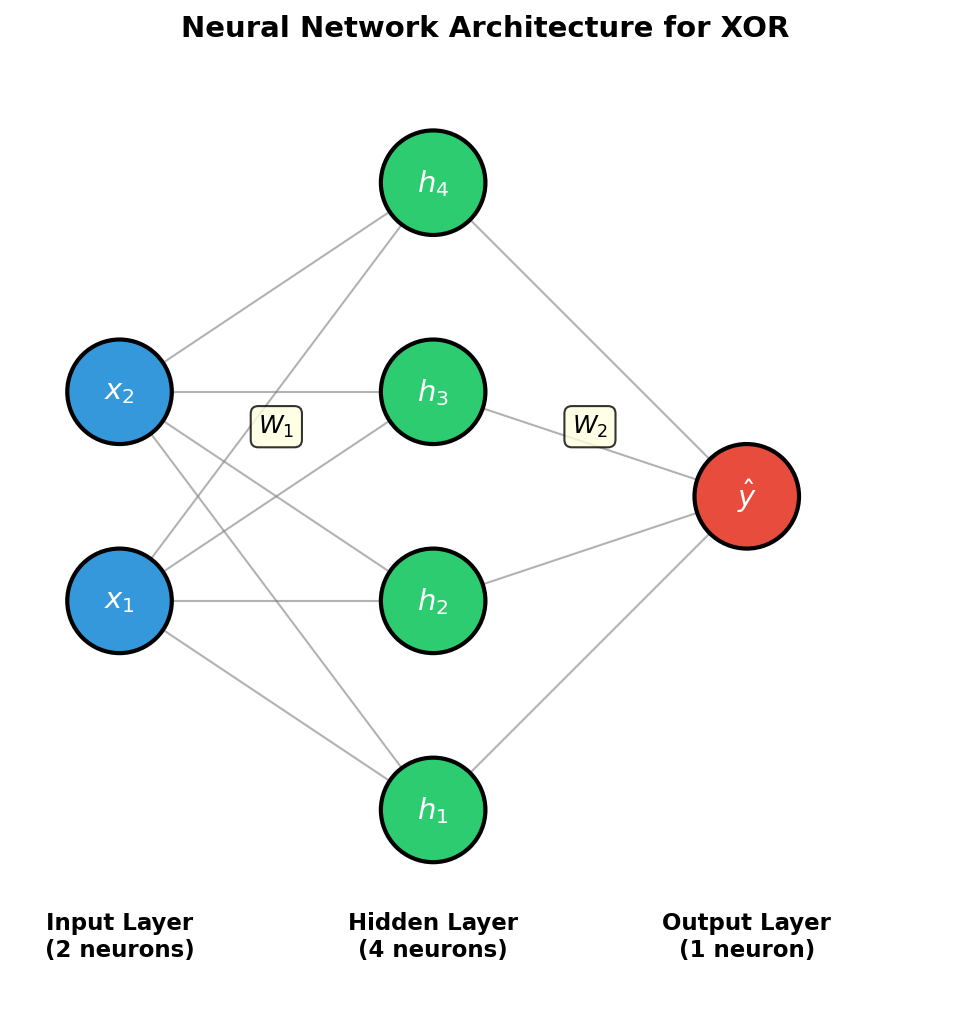
Part 1 — The architecture of a multi-layer network
A 2-2-1 network has:
- 2 inputs
(x₁, x₂) - A hidden layer of 2 neurons with sigmoid activations
- An output neuron with sigmoid activation
- 9 parameters total: 4 input→hidden weights, 2 hidden biases, 2 hidden→output weights, 1 output bias
The replacement of the step function with the sigmoid is the key. Sigmoid is smooth and differentiable everywhere; the step function is not. Gradient-based learning needs derivatives — and only continuous activations have them.
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def sigmoid_deriv(z):
s = sigmoid(z)
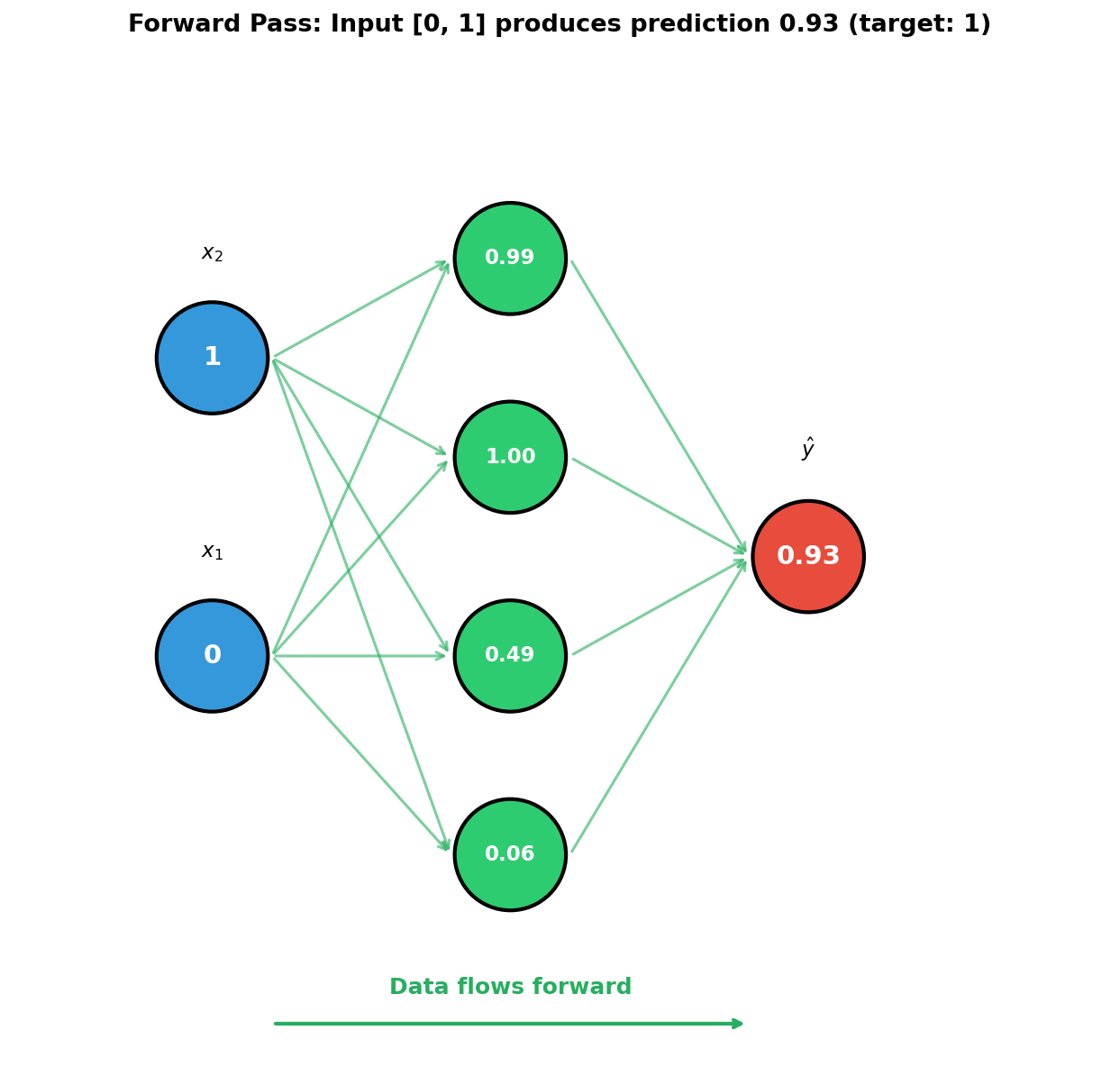
return s * (1 - s)Part 2 — Forward pass
Compute the hidden activations then the output:
def forward(self, x):
z1 = W1 @ x + b1 # hidden pre-activation
h = sigmoid(z1) # hidden activation
z2 = W2 @ h + b2 # output pre-activation
y = sigmoid(z2) # output activation
return y, (z1, h, z2) # also cache for backpropThe cache (z1, h, z2) is essential — backprop needs these values to compute derivatives without redundant recomputation.
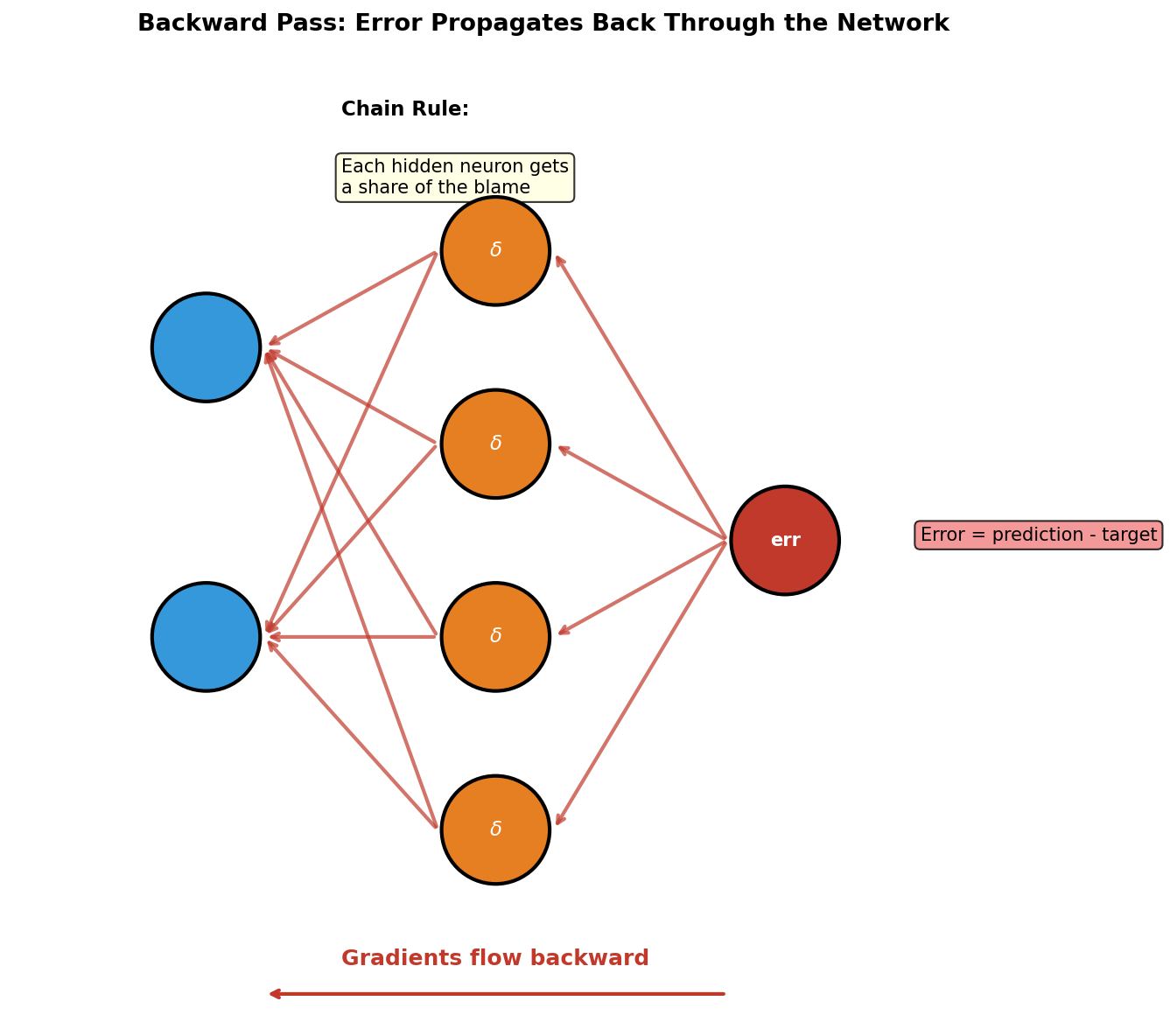
Part 3 — Backward pass via the chain rule
The loss for one training example is squared error:
L = (y_pred − y_true)²We want ∂L/∂w for every weight w. The chain rule propagates the error backward through each operation:
def backward(self, x, y_true, cache):
z1, h, z2 = cache
y_pred = sigmoid(z2)
dL_dy = 2 * (y_pred - y_true) # ∂L/∂y_pred
dy_dz2 = sigmoid_deriv(z2) # ∂y_pred/∂z2
dL_dz2 = dL_dy * dy_dz2 # combine
dL_dW2 = np.outer(dL_dz2, h) # output weights
dL_db2 = dL_dz2 # output bias
dL_dh = W2.T @ dL_dz2 # error at hidden activations
dL_dz1 = dL_dh * sigmoid_deriv(z1) # combine with sigmoid deriv
dL_dW1 = np.outer(dL_dz1, x) # input weights
dL_db1 = dL_dz1 # hidden biases
return dL_dW1, dL_db1, dL_dW2, dL_db2Each line is one application of the chain rule. The genius of backprop is reusing the cached forward activations to avoid recomputing them [2, 3].
Synthesis project
Train on XOR
Run simple_xor_train.py. The script initialises a 2-2-1 network with random weights and trains for 5000 epochs using batch gradient descent. The script saves a sequence of decision-boundary images as training progresses.
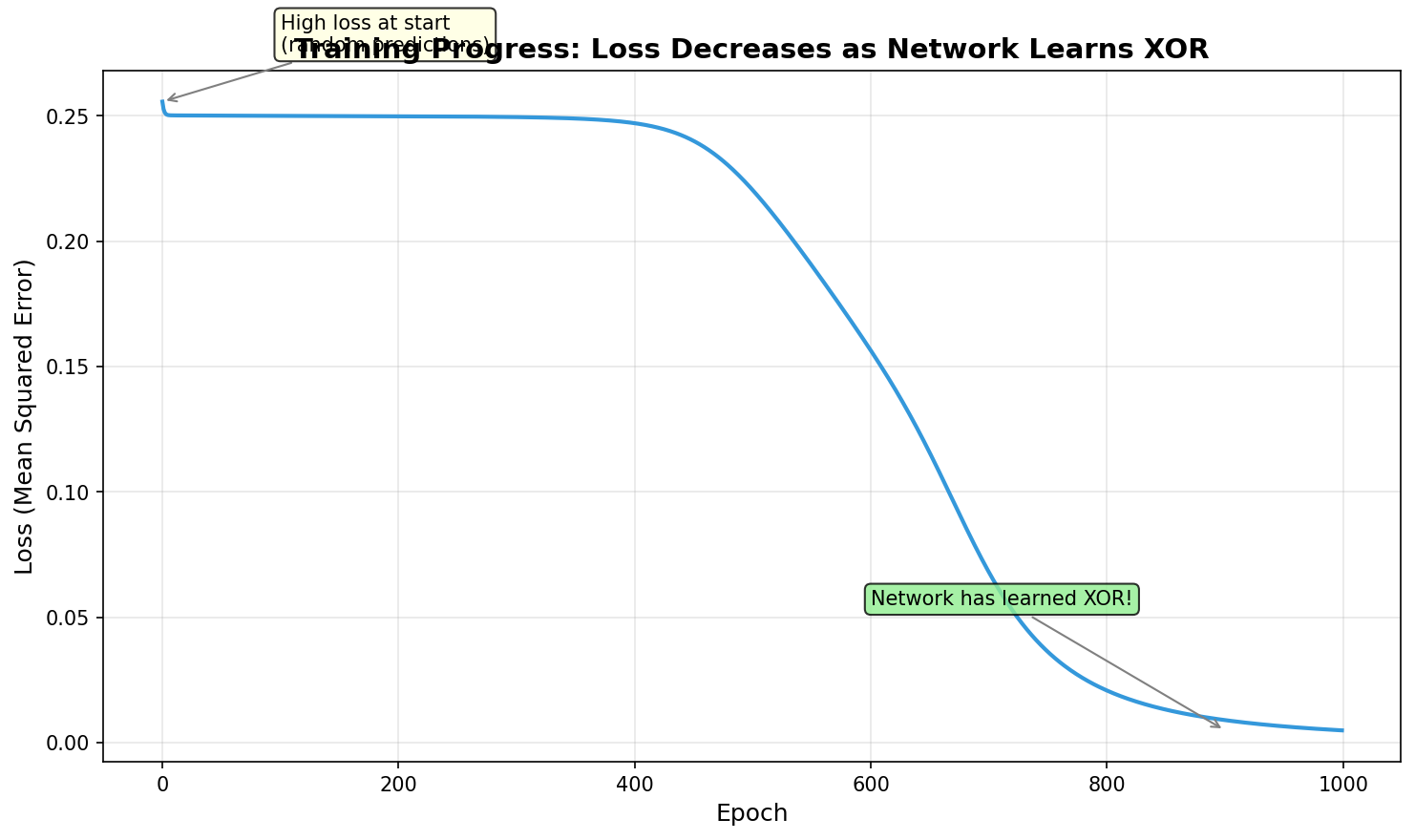
Reflection questions
- Why does the loss curve have a long plateau near the start?
- Why is the final boundary curved, not straight?
- What happens if you initialise all weights to zero?
Answers
Plateau — at random initialisation, the sigmoid outputs are near 0.5, gradients are small, and the network needs many epochs to escape the initial flat region. This is the classic “vanishing gradient” warmup.
Curved boundary — the hidden layer transforms the 2D input space into a 2D hidden space where XOR is linearly separable. The output sigmoid draws a line in the hidden space; pulled back to the input space, that line becomes a curve.
Zero init — all hidden neurons compute identical outputs, gradients are identical, and updates are identical. The network never differentiates the hidden neurons; XOR remains unsolved. This is why neural networks always use random initialisation.
Three architecture experiments
Edit simple_xor_train.py to try these variations.
Goals
- More hidden neurons — bump from 2 to 8. Faster convergence? Smoother boundary?
- Different activation — replace sigmoid with
tanh(and its derivative1 − tanh²). - Larger learning rate — bump
lrfrom 0.5 to 5.0. Watch for divergence.
Expected outcomes
- 8 neurons: dramatically faster convergence, boundary still works. Most modern networks have far more parameters than data points — XOR is a contrived edge case.
- Tanh: converges faster than sigmoid because tanh’s gradients are centred at zero, and tanh saturates more slowly. (This is why tanh largely replaced sigmoid in the 1990s.)
- Huge LR: the loss may oscillate or explode. The fix is to drop LR back down — the same balancing act every neural network trainer has to do.
Replace XOR with a circle dataset
Generate a dataset where one class is a disc and the other is the surrounding annulus. Train the same 2-2-1 network. Plot the learned decision boundary.
Hint and outcome
rng = np.random.default_rng(0)
N = 200
inside = rng.normal(0, 0.5, (N, 2))
outside = rng.normal(0, 1.6, (N, 2))
outside = outside[np.linalg.norm(outside, axis=1) > 1.2]
X = np.vstack([inside, outside])
y = np.concatenate([np.ones(len(inside)), np.zeros(len(outside))])Two hidden neurons can carve out a rough disc boundary, but bumping to 4+ neurons gives a much cleaner circle. The exercise demonstrates that the expressive power scales with hidden-layer width — the Universal Approximation Theorem (1989) proved that one hidden layer with enough neurons can approximate any continuous function [5].
Downloads
simple_xor_train.py — train + plot training backprop_solution.py — reference implementationReferences
- [1] Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323(6088), 533–536. doi:10.1038/323533a0
- [2] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- [3] Nielsen, M. A. (2015). Neural Networks and Deep Learning. Determination Press. neuralnetworksanddeeplearning.com
- [4] Werbos, P. J. (1974). Beyond regression: New tools for prediction and analysis in the behavioral sciences. PhD dissertation, Harvard University.
- [5] Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals, and Systems, 2(4), 303–314.
- [6] LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444.