9.1.1 Perceptron from Scratch
Build Rosenblatt's 1958 perceptron in NumPy: a linear weighted sum, a step activation, and the weight-update rule that adjusts inputs after every wrong prediction. Train it as a binary classifier on a 2D dataset.
Big question
What is the simplest machine that can learn to classify data? Frank Rosenblatt’s 1958 perceptron is the answer — and it is so simple you can implement it in thirty lines of NumPy. Three operations: multiply inputs by weights, sum the products, threshold the result. The novel addition was a learning rule: after every wrong prediction, nudge each weight in the direction that would have produced the right answer. Run this loop on linearly separable data and the weights converge to a hyperplane that splits the two classes [1, 2]. The same weight-update logic, generalised through calculus, runs inside every modern neural network with billions of parameters.
Learning objectives
- State the perceptron architecture: weighted sum, bias, step activation.
- Implement the forward pass with
np.dotand a step function. - Apply the perceptron learning rule:
w ← w + lr × (y_true − y_pred) × x. - Visualise the learned decision boundary as a line in 2D feature space.
- Recognise the XOR limitation that motivated multi-layer networks.
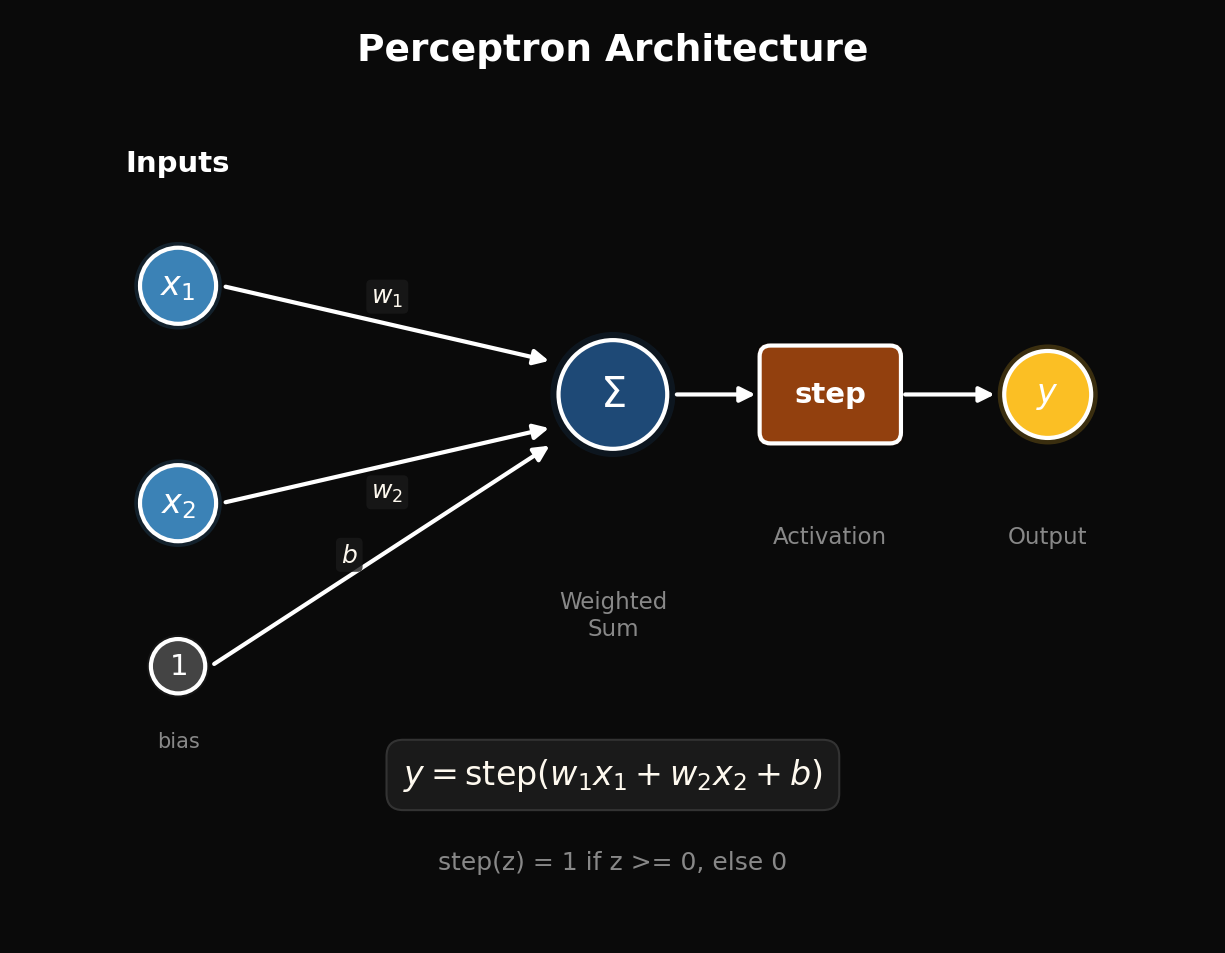
Part 1 — Architecture of a perceptron
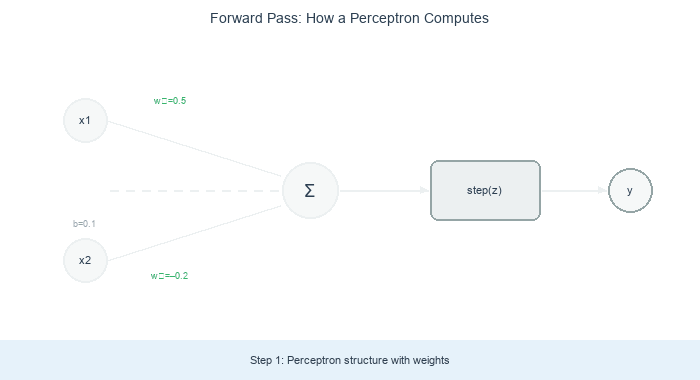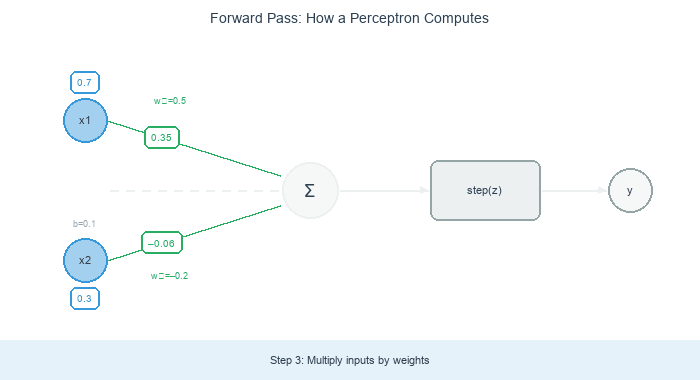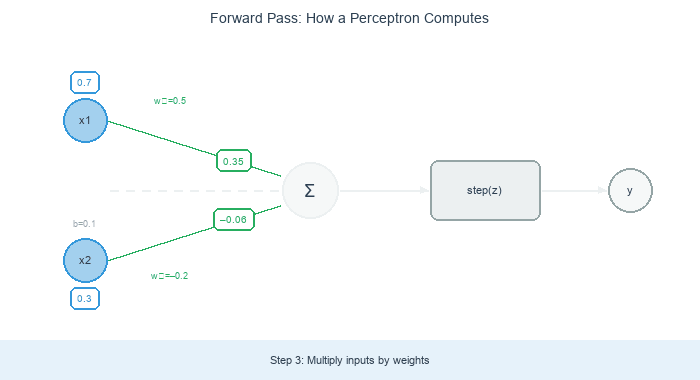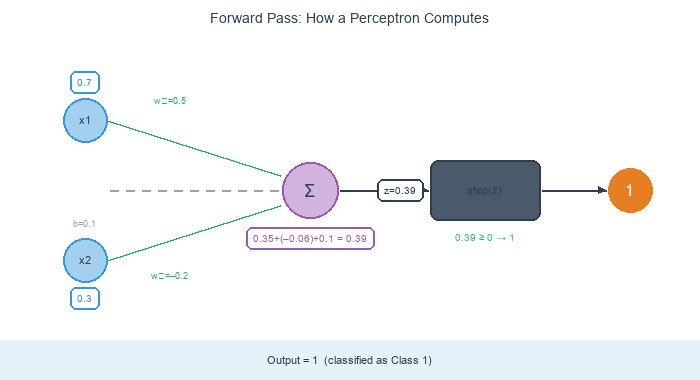
A perceptron takes n numeric inputs (x₁, …, xₙ), multiplies each by a learned weight wᵢ, sums the products with a bias term b, and applies a step function:
def forward(self, x):
z = np.dot(self.weights, x) + self.bias
return 1 if z >= 0 else 0That is the entire forward pass. The weighted sum is a single dot product; the step function is one if statement. The “neural” feel comes from analogy with McCulloch and Pitts’s 1943 biological neuron model: dendrites collect weighted inputs, the cell body integrates, the axon fires (1) when the total exceeds a threshold [3].
Part 2 — The forward pass on real data
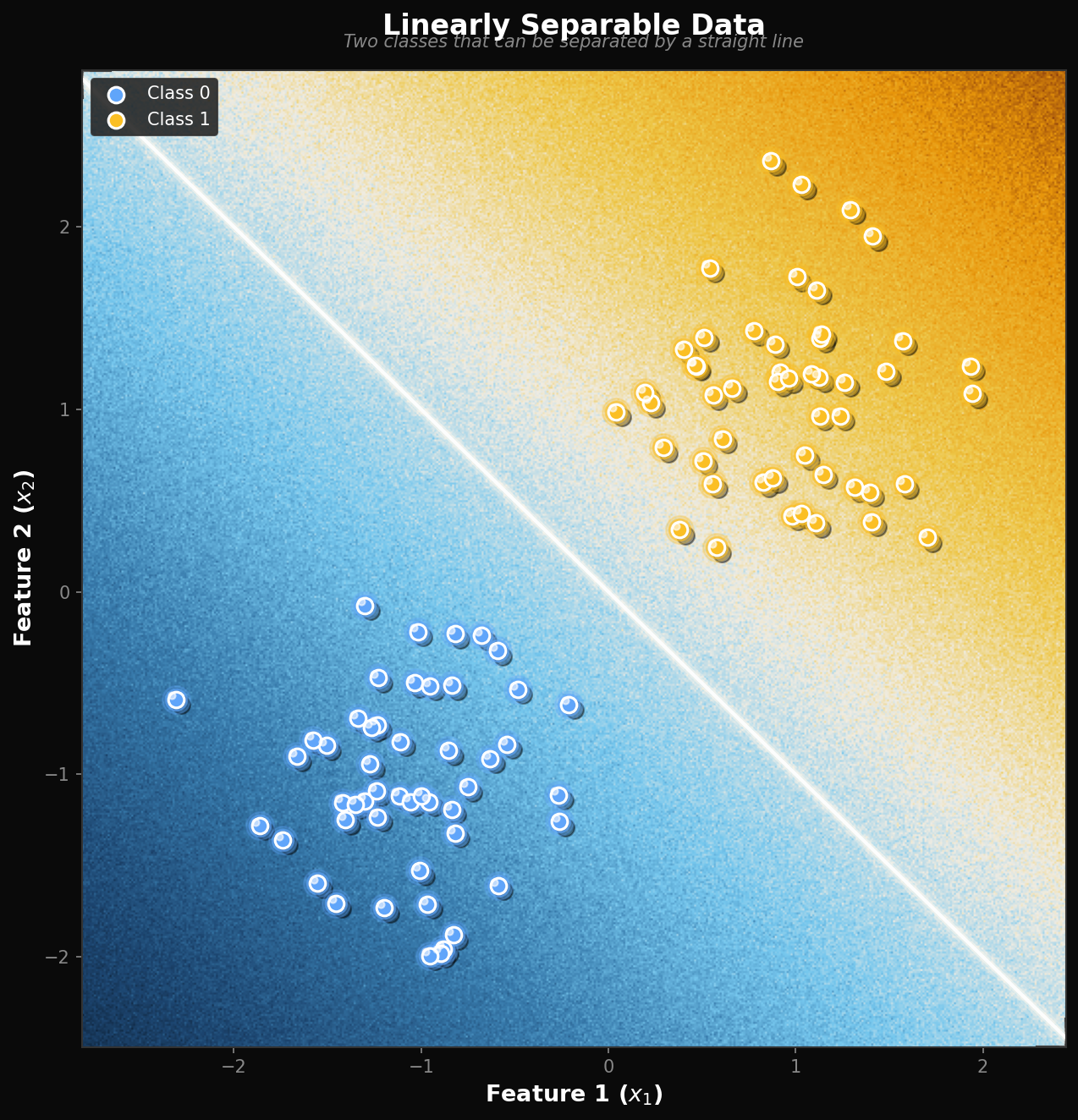
A trained perceptron’s decision rule is simple geometry: draw a line through the feature space defined by w₁ x₁ + w₂ x₂ + b = 0. Points on one side score positive (class 1); points on the other side score negative (class 0).
For a separable two-class problem (the classic “linearly separable” setup), there is at least one line that perfectly splits the classes. The perceptron learning rule promises to find it.
Part 3 — The learning rule
Rosenblatt’s 1958 weight-update rule is one line:
def update(self, x, y_true, lr=0.1):
y_pred = self.forward(x)
error = y_true - y_pred
self.weights += lr * error * x
self.bias += lr * error- If the prediction is correct,
error = 0and nothing changes. - If the perceptron missed,
erroris±1and weights are pushed in the direction that would have produced the correct sign. - The learning rate
lrscales the size of each update.
Novikoff’s theorem (1962) proves this rule converges to a separating hyperplane in finite steps if one exists. The number of updates is bounded by (R/γ)² where R is the data radius and γ the margin [4].
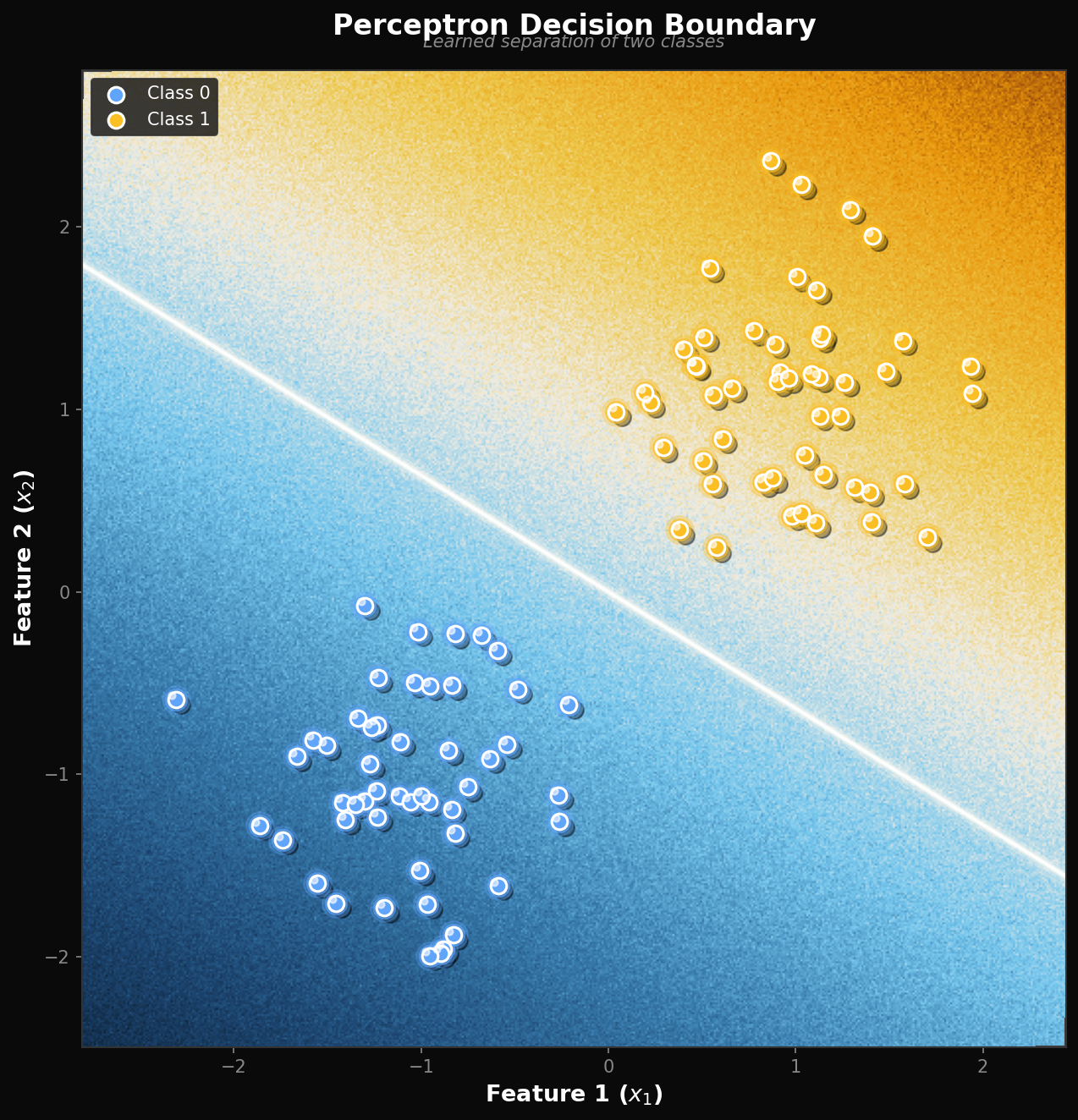
Synthesis project
Train a perceptron on linearly separable data
Run simple_perceptron.py from the downloads. It generates a 2D dataset (two Gaussian blobs), trains a perceptron for 50 epochs, and plots the decision boundary.
Reflection questions
- Why does the line stop moving after some number of epochs?
- What does the learning rate control, and what goes wrong if it’s too large or too small?
- The trained line is one valid separator; there are infinitely many others. Which one does the perceptron find?
Answers
Stopping — once every training point is classified correctly, the error term is zero for all of them, so weights stop updating. The perceptron has converged.
Learning rate — controls update step size. Too small → very slow convergence. Too large → may overshoot and oscillate around the optimum (especially for noisier data). For separable data the convergence proof is rate-insensitive; for real data the rate matters a lot.
Which line? — the first one the perceptron happens to land on as it processes training points. Different initial weights or different shuffling order give different separating lines. (SVMs add a max-margin objective; perceptrons don’t care about margin, only correctness.)
Three perceptron experiments
Edit simple_perceptron.py to:
Goals
- Smaller learning rate — drop
lrfrom 0.1 to 0.01. Track epochs to convergence. - Different starting weights — initialise with
weights = np.zeros(2)vsweights = np.random.randn(2). Compare the final lines. - Non-separable data — generate two overlapping clusters; observe that the perceptron never converges (the proof’s premise breaks).
Expected outcomes
- Slow rate: same final line, ~10× more epochs.
- Different inits: both converge but to different separating lines, demonstrating non-uniqueness.
- Non-separable: the weights oscillate forever; the algorithm cycles through misclassifications without settling. This is exactly the case Minsky and Papert called out — and where multi-layer networks (next lesson) earn their keep.
The XOR problem — and why it fails
Build a perceptron and train it on the XOR dataset: (0,0)→0, (0,1)→1, (1,0)→1, (1,1)→0. Plot the decision boundary after 1000 epochs.
import numpy as np
import matplotlib.pyplot as plt
class Perceptron:
def __init__(self, n_in):
self.w = np.zeros(n_in)
self.b = 0.0
def forward(self, x):
return 1 if np.dot(self.w, x) + self.b >= 0 else 0
def update(self, x, y, lr=0.1):
pred = self.forward(x)
err = y - pred
self.w += lr * err * x
self.b += lr * err
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=float)
y = np.array([0, 1, 1, 0])
p = Perceptron(2)
# TODO: train for 1000 epochs, shuffling each epoch.
# TODO: plot data points and the (failed) decision line.Expected result + explanation
The perceptron will not converge. The four XOR points are not linearly separable: no straight line can put (0,0) and (1,1) on one side and (0,1) and (1,0) on the other. The weights oscillate; the decision line never settles on a useful position. This is the 1969 Minsky-Papert problem in exactly four data points. The fix is to add a hidden layer — exactly what 9.1.2 introduces with backpropagation.
Downloads
simple_perceptron.py — train + plot the boundary perceptron_solution.py — reference implementationReferences
- [1] Rosenblatt, F. (1958). The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386–408. doi:10.1037/h0042519
- [2] LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444. doi:10.1038/nature14539
- [3] McCulloch, W. S., & Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activity. The Bulletin of Mathematical Biophysics, 5(4), 115–133.
- [4] Novikoff, A. B. J. (1962). On convergence proofs on perceptrons. Symposium on the Mathematical Theory of Automata, 12, 615–622.
- [5] Minsky, M., & Papert, S. (1969). Perceptrons: An Introduction to Computational Geometry. MIT Press.
- [6] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. deeplearningbook.org